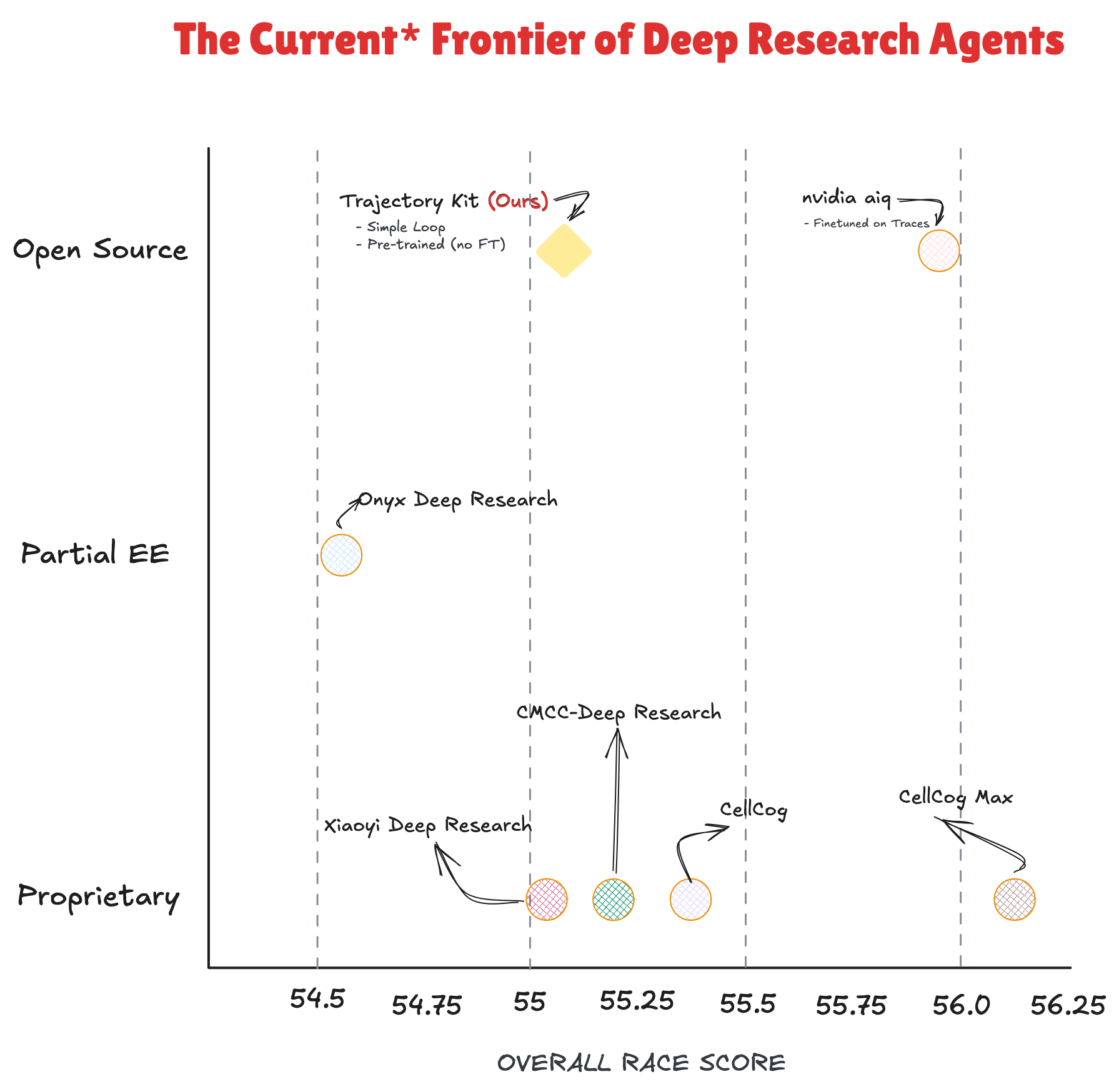
This reflects the state of DeepResearch-Bench as of late March 2026. These numbers will almost certainly have moved by the time you read this, and that is a good thing for the field.
- Score: 55.08 on DeepResearch-Bench, competitive with frontier systems
- Model: Pre-trained GPT-OSS-20B model; no specialised fine-tuning
- Architecture: Focus on harness design, not model size
- Approach: Recursive delegation, verification pipelines, and fallback search strategies
- Key insight: Good system design can match larger, fine-tuned competitors
The Result That Made Us Look Twice

Deep research agents are getting good fast. TrajectoryKit (Ours) scored 55.08 on DeepResearch-Bench, ahead of every proprietary system in the figure above, and the highest score among open source systems that use no fine-tuning. Only nvidia aiq, fine-tuned on research traces, and CellCog Max (closed-source, proprietary) score higher overall, by less than 1 point.
What that position does not show is how we got there. TrajectoryKit is a pre-trained 20B model in a simple loop with no fine-tuning on research traces. No weight modifications, no proprietary inference stack. The entire system runs on vLLM endpoints with our harness managing state. Every system above us on this chart either used a larger model, fine-tuned on research trajectories, or both.
We wanted to understand how far good harness design alone could take a pre-trained model. This post is about what we found, and what we are still not sure about.
⚡ Get started with TrajectoryKit
What Is a Deep Research Agent?
A deep research agent takes a hard question (the kind that would inspire a 7+ hour lock-in session to solve) and autonomously searches, reads, synthesises, and writes a cited report. Think "What structural shifts in the music industry made it possible for a bedroom producer to outperform a major label release in 2024?" rather than "Who produced Kendrick Lamar's last album?"
The difficulty is not just retrieval. It is also knowing what to look for, how to chain findings across sources, when a claim needs verification, and how to produce something useful rather than just long. Most competitive systems solve this through fine-tuning on research traces, proprietary tooling, or both. We took a different bet: that good harness design, applied to a strong pre-trained model, could get most of the way there.
How TrajectoryKit Works
TrajectoryKit separates research into four distinct stages: planning, research, drafting, and verification. The entire system runs on top of vLLM -- we are hitting inference endpoints and tracking where we are in the loop. There are no custom model weights, no proprietary inference stack. Just a well-designed harness managing state across a standard serving setup. We opt to use GPT-OSS-20B as our root orcehstrator and subagents, but this can be switched out depending on your needs.
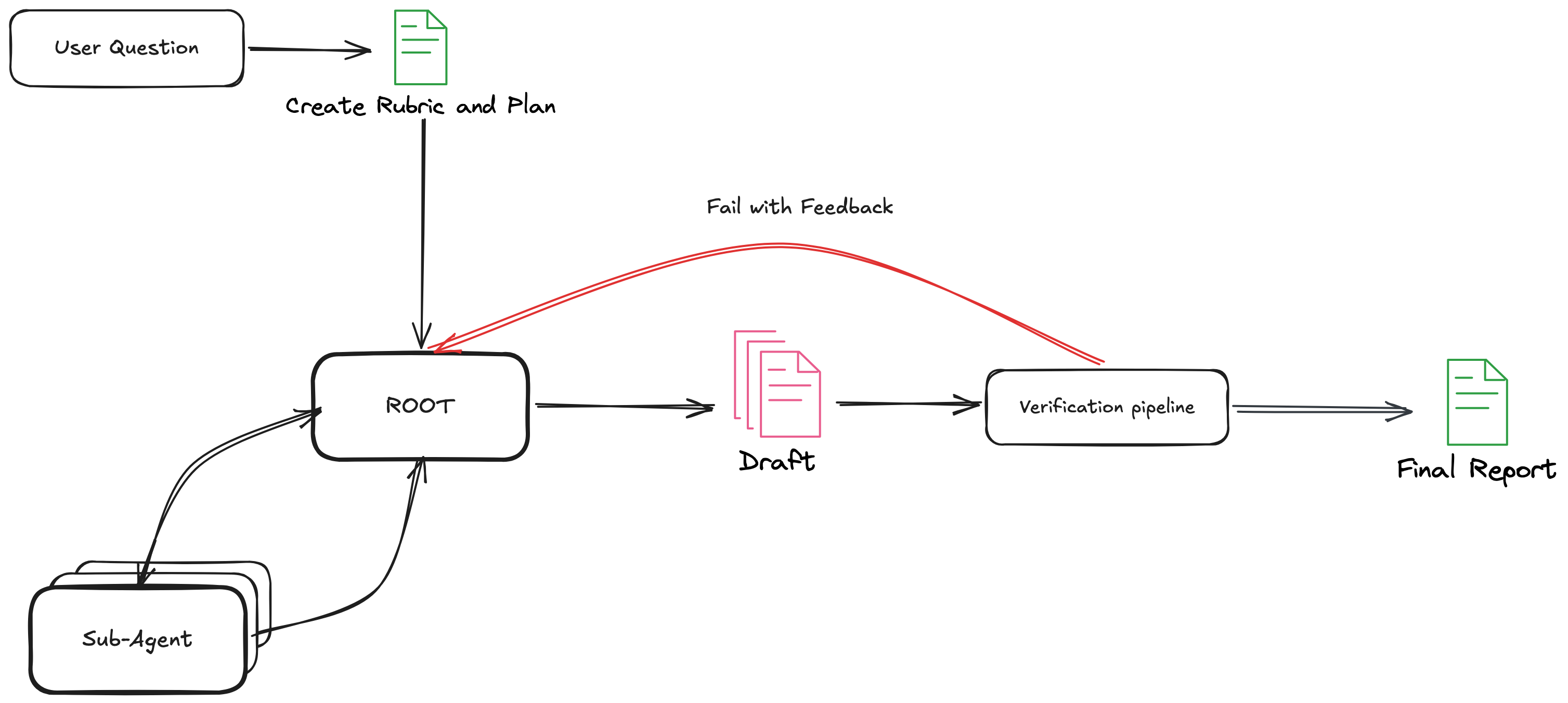
A root orchestrator handles the overall task, delegating research sub-tasks to fresh-context worker agents. Each worker has access to search, fetch, PDF extraction, code execution, and memory tools. The root consolidates their findings into a draft, then hands off to a verification pipeline that decides whether to publish or return the draft to the research loop with specific feedback.
A few design decisions are worth highlighting:
Recursive delegation with fresh context. Each worker agent starts with a clean context window. This prevents the well-known degradation that happens when long agentic loops accumulate noise in context. Workers return structured findings; the root synthesises.
A four-stage verification pipeline. When the root agent believes it has completed
enough research and drafting, it must call the research_complete() tool, which
kickstarts the verification process.
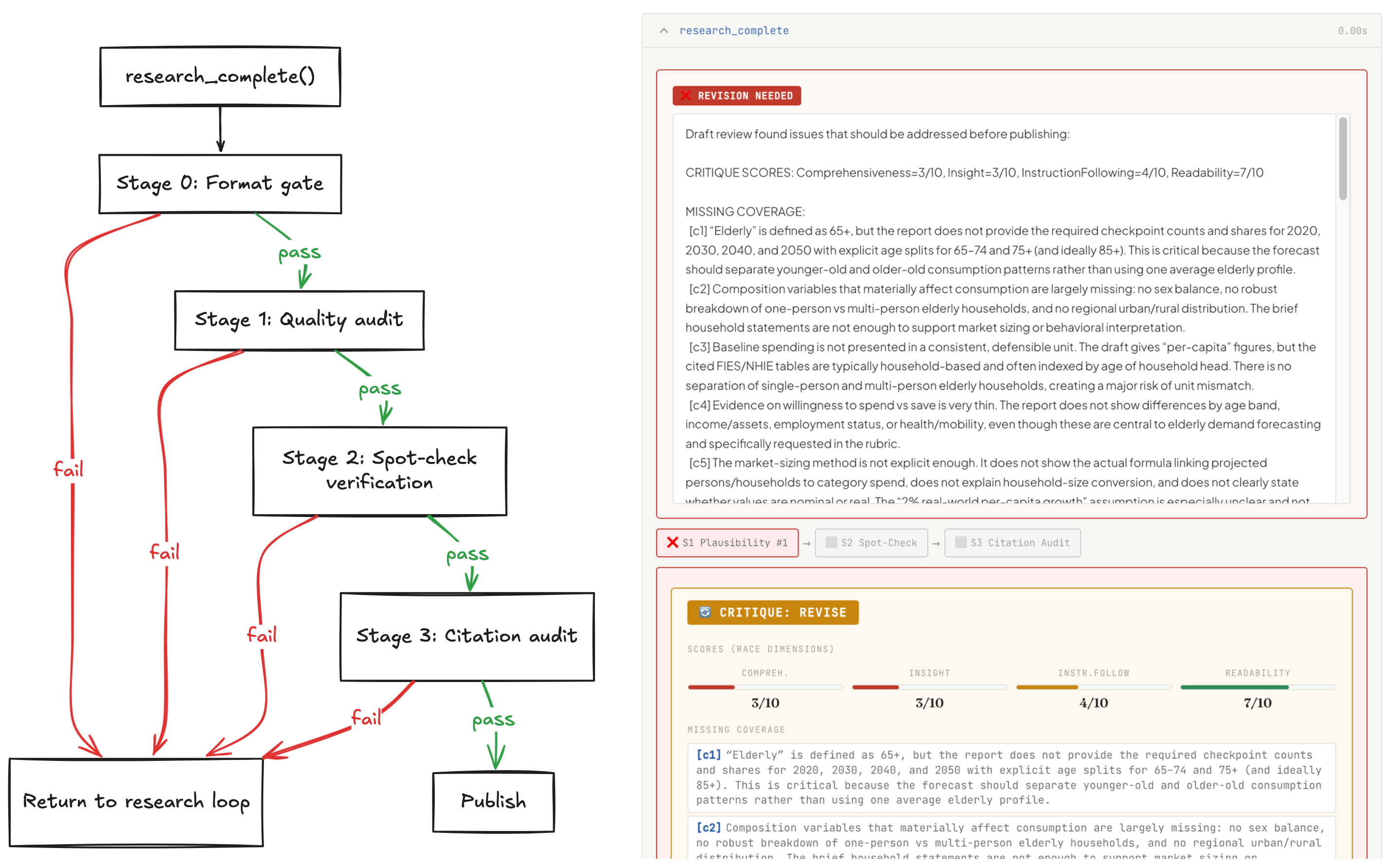 Using the initial rubric and the draft, we task the model with critiquing the format
and content provided and generating structured feedback.
Using the initial rubric and the draft, we task the model with critiquing the format
and content provided and generating structured feedback.
The draft passes through a format gate, a quality audit against a pre-generated rubric, a spot-check stage where claims are extracted and independently verified by sub-agents, and a citation audit confirming that URLs actually resolve and support what is cited. Failure at any stage returns the draft to the research loop with targeted feedback.
What we find most interesting about this design is that it opens up opportunities to study the effects of using a separate LLM as critic, or applying self-critique with the same model. It also creates natural routing points at the root level: for instance, using verification feedback to switch to a stronger model mid-trajectory, or dynamically adapting the agent architecture based on failure mode.
Three-tier search and four-tier fetch fallbacks. Search cascades through Serper, Exa, and DuckDuckGo. Fetch cascades through direct HTTP, Jina Reader, the Exa content API, and the Wayback Machine. This keeps the system running through the API credit exhaustion and rate limits that routinely break long benchmark runs. A bonus is that the Wayback Machine fallback ensures that content has gone offline is still (mostly) reachable.
Causal chain planning. Before the research loop begins, the model reads the question and identifies multi-step dependencies, steps that require an earlier result before they can run. This prevents the agent from attempting synthesis before it has gathered the relevant evidence.
Code execution via isolated sandbox. When the agent needs to compute, aggregate, or transform data during a research run, it generates Python code and dispatches it to a sandboxed execution environment via SandboxFusion. Results are returned as base64-encoded strings, which the agent decodes and integrates into its findings for the next turn. This keeps arbitrary computation out of the main inference loop while giving the agent a genuine scratchpad for quantitative reasoning, something closer in spirit to how Recursive Language Models use intermediate computation via named variables.
See It in Action
Before getting into the numbers, it is worth looking at what the agent actually produces.
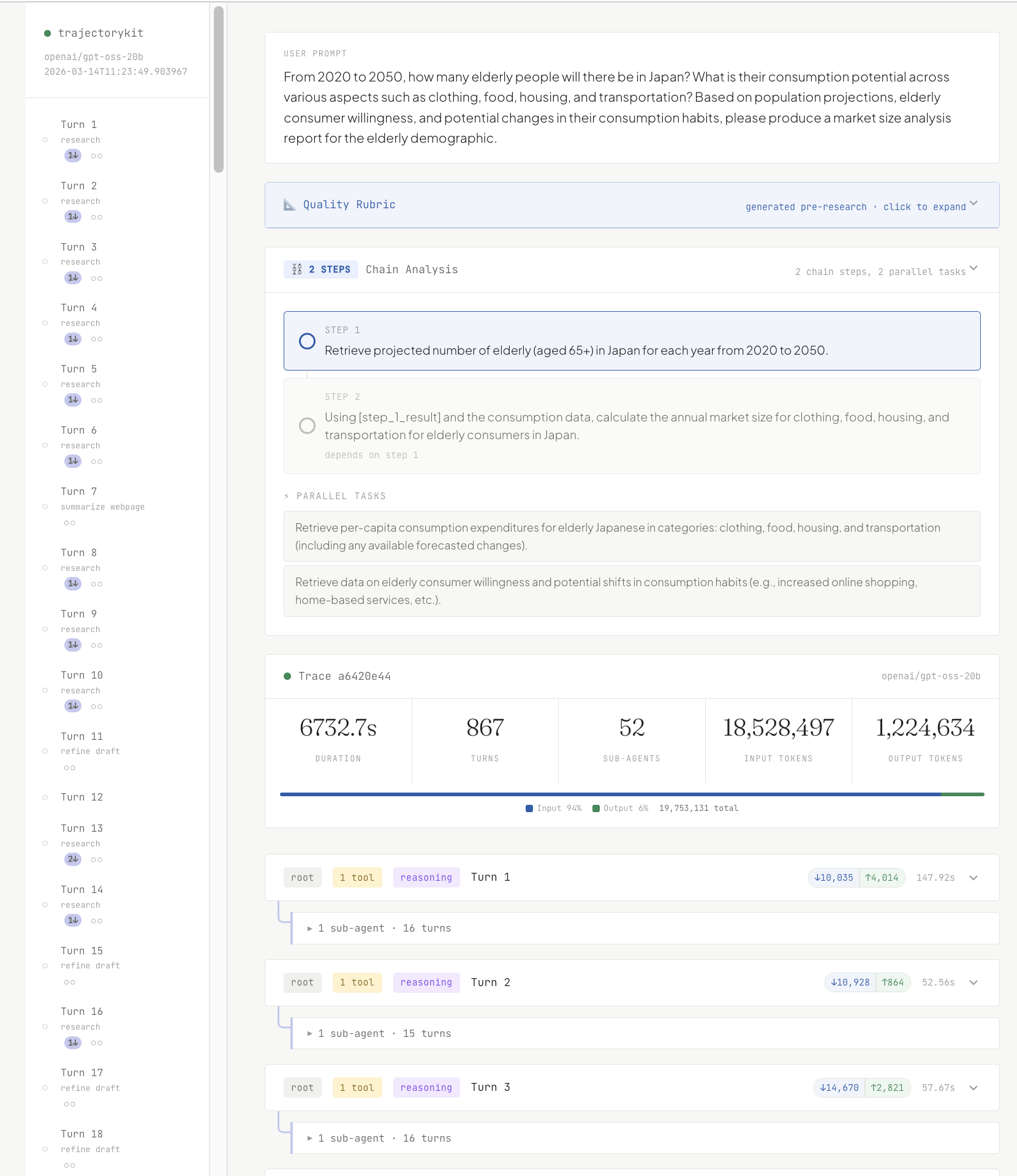
We have published a full annotated trace from a run on producing a market size analysis for Japan's elderly consumer demographic from 2020 to 2050. A question spanning demographic projection, multi-sector economic analysis, and consumption forecasting across a thirty-year horizon, with no single source that covers all of it.
The trace shows every tool call the root and worker agents made, the intermediate drafts, which verification stages triggered feedback loops, and how the final report differs from the first draft. It also tracks token spend across both the global orchestrator and individual sub-agents. It is the most direct illustration of what the harness actually does under the hood.
If you want to get your hands dirty? Check out the GitHub repository to spin up your own research agents.
The Ablation: What Actually Drives Performance
Before we get to the full ablation, it helps to position the raw agent output against a natural baseline: frontier LLMs using web search, but without an agentic harness. Neither side has fine-tuned weights, so this is a direct test of architecture versus raw model capability.
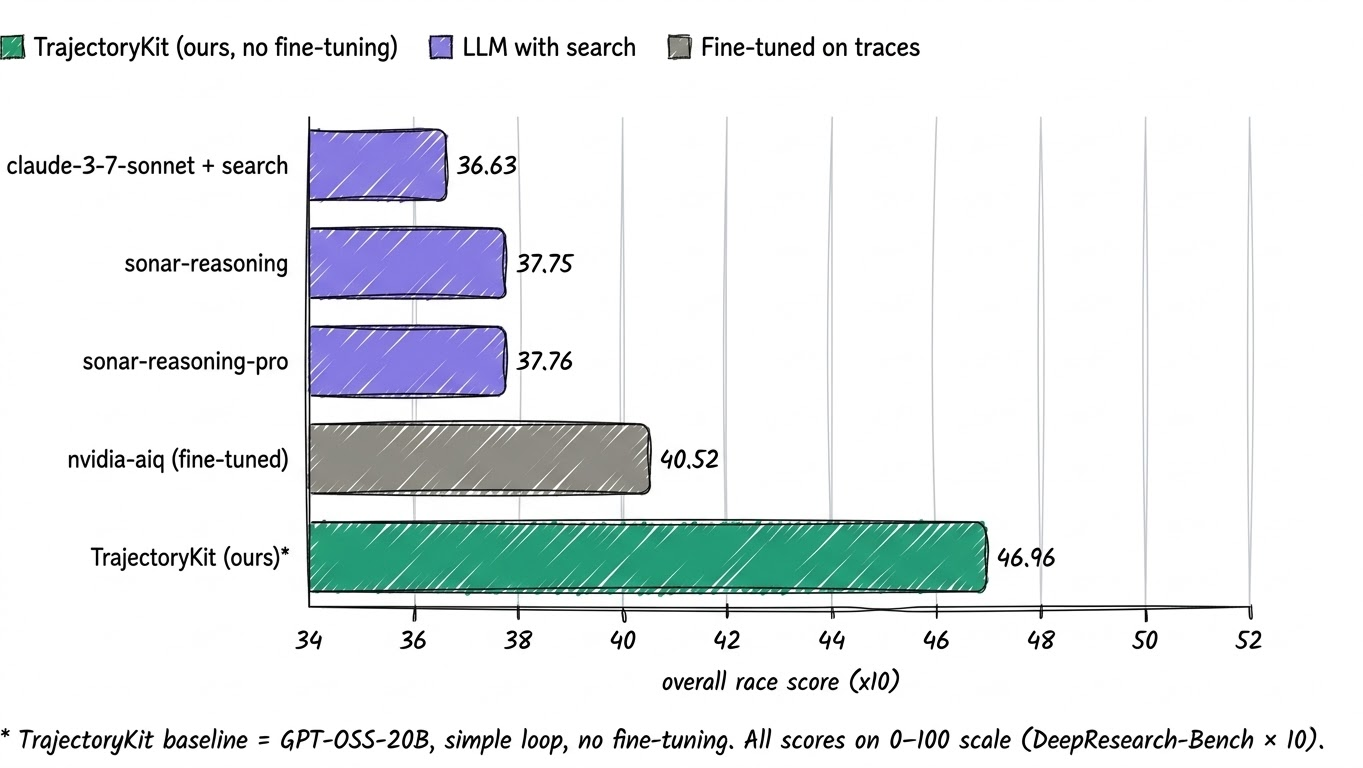
TrajectoryKit's baseline scores 46.96, ahead of every LLM-with-search system in this comparison. The margins over sonar-reasoning-pro at 37.76 and claude-3-7-sonnet-with-search at 36.63 suggest the harness is doing real work, not just handing a strong model a search tool.
From there, we add a rewrite step: after producing a verified draft, we pass it through a stronger model for a final polish. That raises the obvious next question. If the baseline is already ahead, what is rewriting actually adding, and are those gains real?
That is what the three-condition ablation below is designed to test.
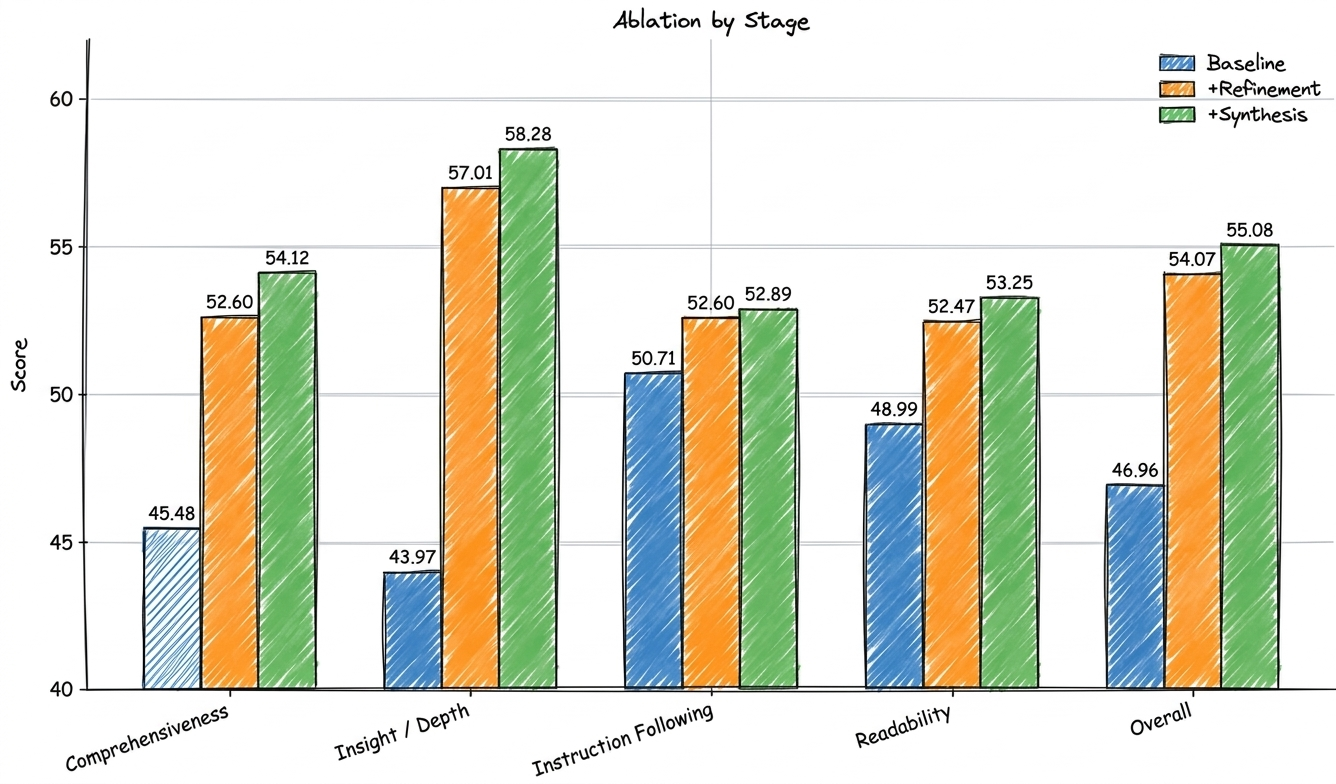
Baseline = raw GPT-OSS-20B agent output. +Refinement = requirement rewriting pass using GPT-5.4. +Synthesis = synthesis and clarity rewriting pass using GPT-5.4. All scores on 0-100 scale.
The pattern is clear. The gains are not coming from a stronger research loop. They are coming from what happens after the loop has already produced a draft. The baseline is the raw agent report, fed into a refinement pass, then passed again into a synthesis pass.
But we want to be honest about what those gains might actually be measuring.
The +32.5% improvement in insight and depth is striking, but it does not come from the research loop gathering better evidence. It comes from GPT-5.4 reshaping a draft that GPT-OSS-20B already produced. The question worth asking is whether that reshaping reflects genuine reasoning improvement, or whether the evaluator -- itself a language model -- simply has a systematic preference for the rhetorical patterns that stronger models produce naturally: more confident hedging, cleaner transitions, more forcefully stated conclusions.
If it is the latter, the benchmark delta is less a signal about the research pipeline and more a signal about model-to-model stylistic preference. The research loop gathered the same evidence either way. The rewriting pass dressed it differently, and the judge preferred the outfit.
This is a broader problem in deep research evaluation that we do not think the field has fully reckoned with. RACE and similar metrics are scored by language models. A report that scores well on insight might simply be one written in the style a larger model prefers, regardless of whether the underlying reasoning is any better.
We are not saying the rewriting passes add no value. Looking at the traces directly, the synthesis pass does meaningfully restructure arguments and surface connections that the raw draft leaves implicit. But we are cautious about how much weight to put on the benchmark delta until we have evaluation methods that can separate rhetorical polish from genuine reasoning quality.
Eval Awareness: An Interesting Edge Case
Early in this project, we observed a phenomenon similar to one documented by Anthropic: our agent searched for and retrieved ground-truth answers directly from the hosting page of DeepSearchQA, a Google deep search benchmark. The immediate fix is straightforward: block the domains hosting benchmark datasets. But the episode points to a deeper challenge: how do we reliably evaluate agents on long-horizon tasks when those agents are capable enough to locate and exploit the evaluation data itself? More troubling still, it raises the question of whether capable agents can now recognise benchmark-style questions and adjust their behaviour accordingly, even without access to the answers. Either way, it suggests that how we design and serve benchmarks may need to keep pace with the agents we are trying to evaluate.
What Did Not Work
Context bleed in long runs. Even with fresh-context workers, the root agent's own context grows across a long session. Our compaction strategy preserves the system prompt and recent turns, stashing older tool outputs in an external memory store. This works in most cases, but the root occasionally loses track of earlier synthesised findings. We are actively improving this.
Verification loop overhead. The four-stage pipeline is thorough, but it adds latency. For questions where the first draft is already strong, the overhead is unnecessary. We are exploring a lightweight pre-check that skips the full pipeline when confidence is high.
Benchmark score versus actual usefulness. A report that scores well on comprehensiveness can still be frustrating to read if it has no clear point of view. The ablation results above sharpen this concern: if benchmark gains are partly model-preference artefacts, we need evaluation methods less susceptible to that confound. We are thinking about what a cleaner framework would look like, one that scores coverage, reasoning validity, and rhetorical quality on separate axes rather than collapsing them into a single model-judged number.
What Next ?
TrajectoryKit is an applied research artifact for my DPhil work on trustworthy agentic systems, but it is also a standalone library and I hope people experiment with it. Current priorities include:
- Stateful, versioned plan objects the root can revise mid-run
- Moving the rewriting passes inside the verification loop so they benefit from rubric feedback
- Giving the verifier and rewriter live web access during their passes
- Broader benchmark coverage, including DeepSearchQA
If you are working on agentic evaluation or building deep research agents, I would love to hear from you.
To Cite This
@misc{lugoloobi2026trajectorykit,
author = {Lugoloobi, William},
title = {We Built a Competitive Deep Research Agent Without Fine-Tuning},
year = {2026},
url = {https://williamlugoloobi.com/blog/building-trajectorykit}
}